
Backgrounds
- NLP 모델의 발전 과정
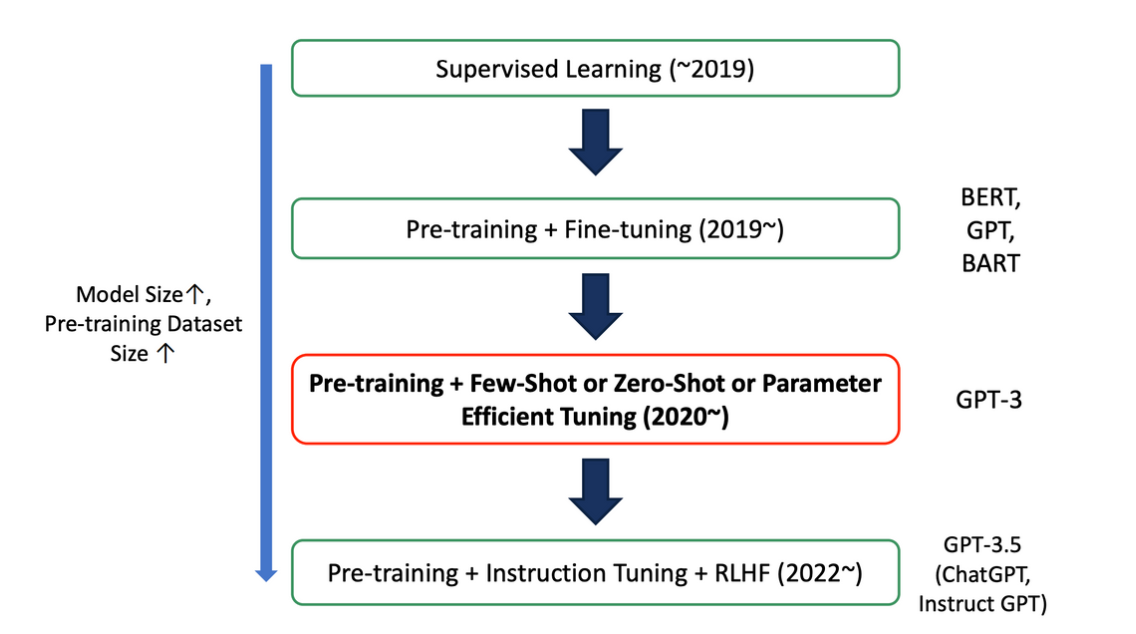
→ 모델과 데이터의 사이즈가 커짐에 따라 전체 데이터만 사용하는 방식이 아닌 다양한 방식이 도입되었음
→ 그 중 PELT는 2020년 이후로 많이 사용되었음
- Prompt-based Fine-tuning: 새로운 파라미터가 필요없고, few-shot 학습에 용이함
- In-context Learning: task에 따라 모델의 파라미터를 바꾸는 것이 아닌, 몇개의 example만을 가지고 학습하는 방식
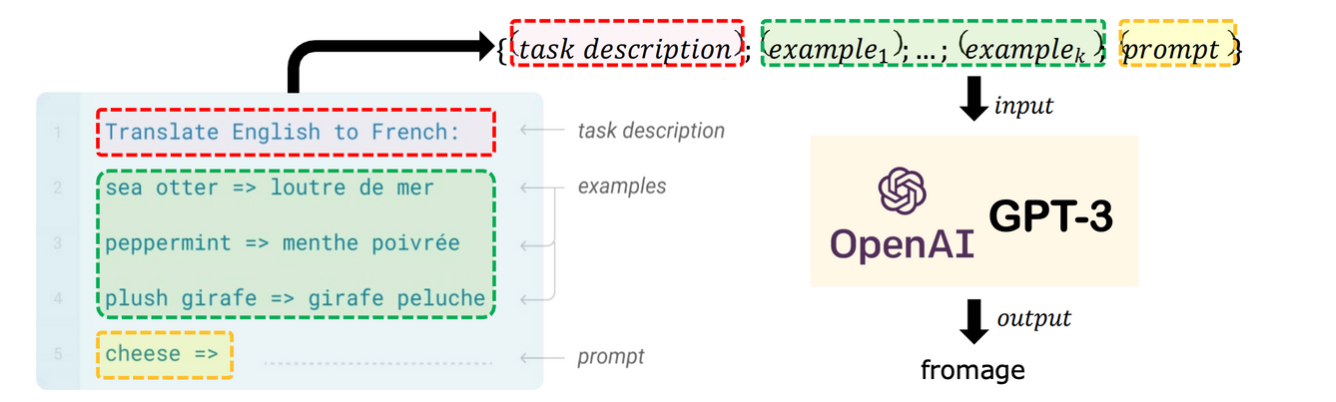
: prompt, demonstrations, pattern, verbalizer(label과 text를 mapping해주는 함수)의 개념 활용
⇒ No task-specific training이 가능하다는 장점이 있지만, 대규모 training set를 활용할 수 없고, manually 하게 쓰여진 prompt는 best가 될 수 없음. 또한 smaller LM에 대해서는 일반화가 어려움
PELT: Parameter-Efficient LM Tuning
- parameter를 효율적으로 학습하기 위한 방법론들
- Full Fine-Tuning의 경우, 기존의 모델들에 task에 맞는 Layer를 추가하여 전체를 재학습 시켜야 했음
→ 실제로 GPT-3를 Full Fine Tuning하려면 1TB의 체크포인트와 v100 최소 96개 이상이 필요함
→ 따라서 each task마다 each model을 사용: 시간 비용 많이 소요
- 이를 해결하기 위하여 파라미터 일부만 training 시킴 (비용 절감)→ 다수의 parameter들은 frozen시킨후, task에 맞게 일부 parameter만 training 시킴
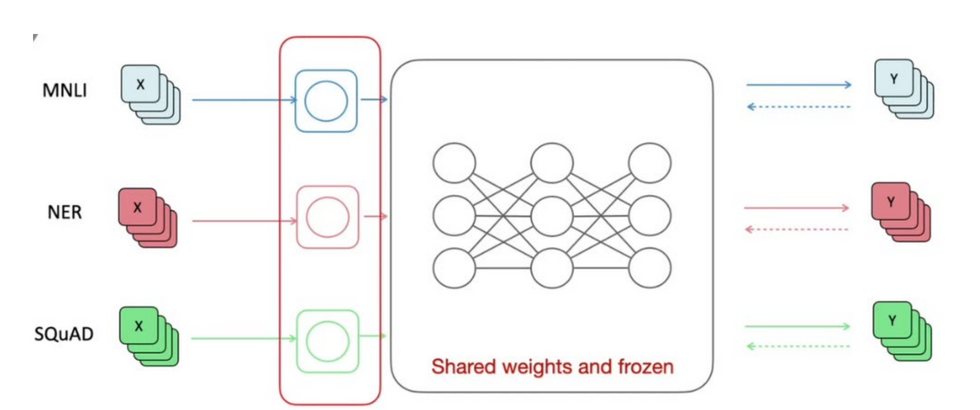
- Transformer를 다음과 같은 방식으로 효율적으로 학습 시킴(Houlsby et al., Parameter-Efficient Transfer Learning for NLP, ICML 2019) ⇒ 뒤에 자세히
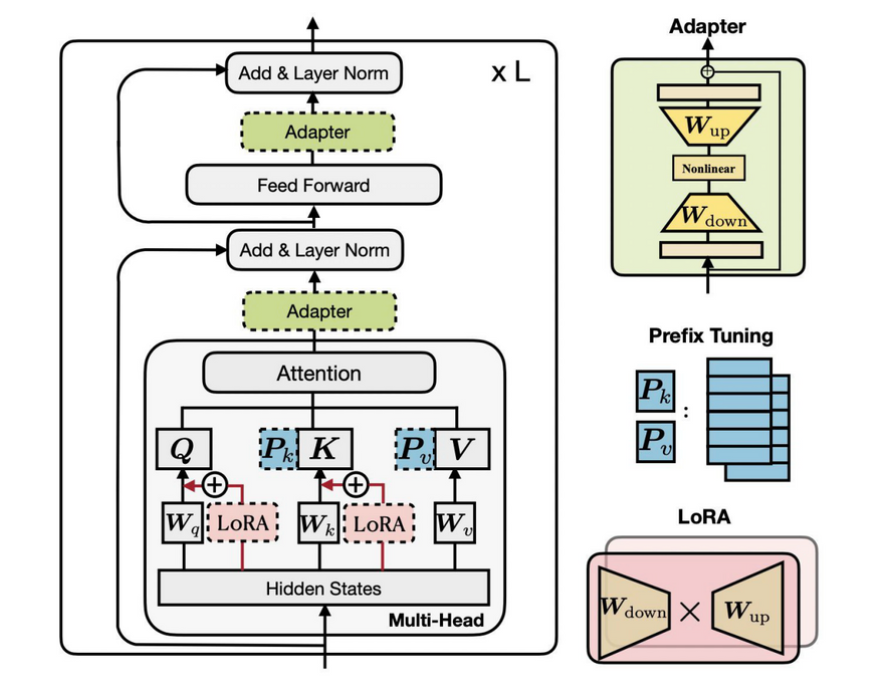
⇒ Adapter, LoRA, Prefix Tuning
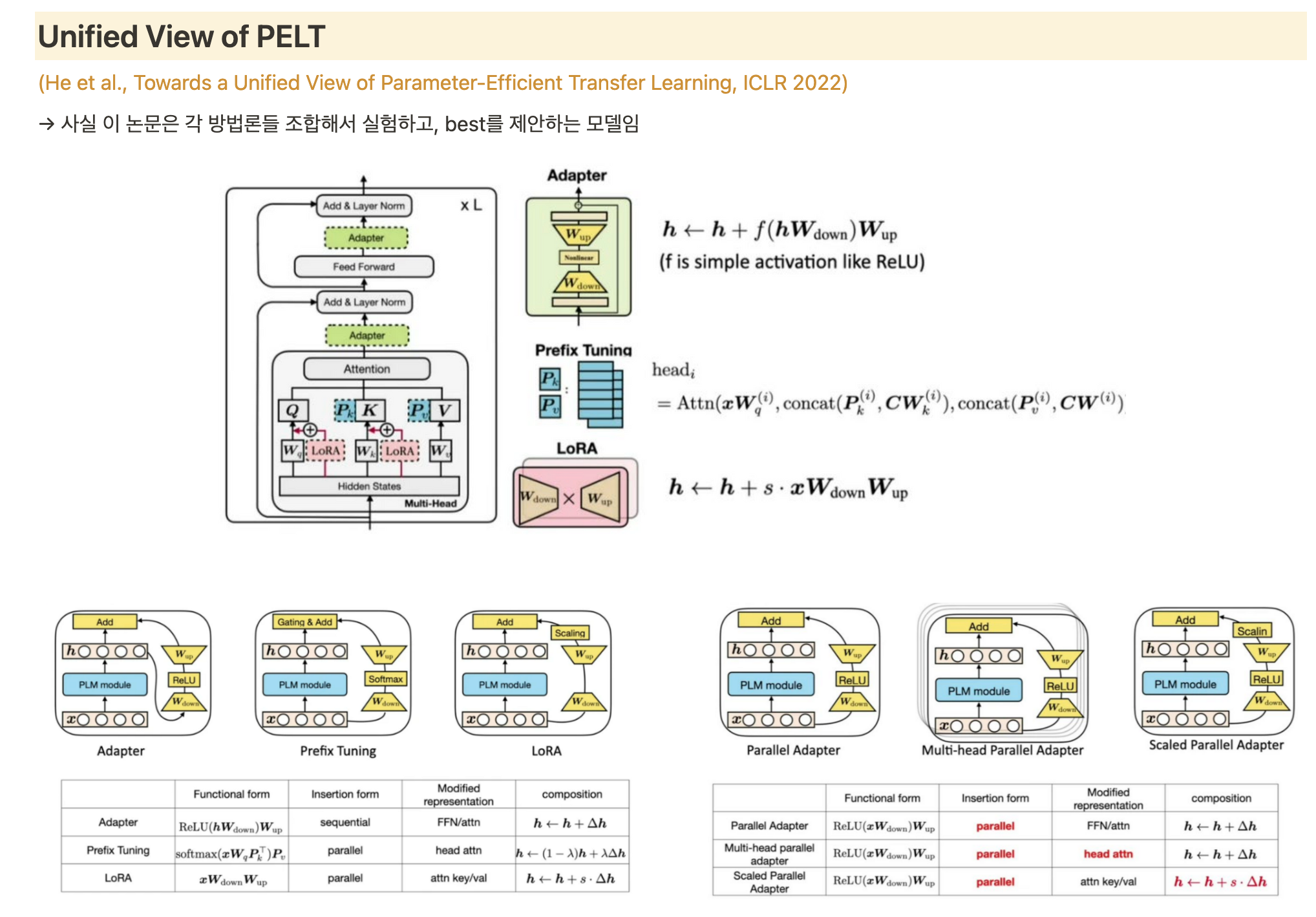
Adapter
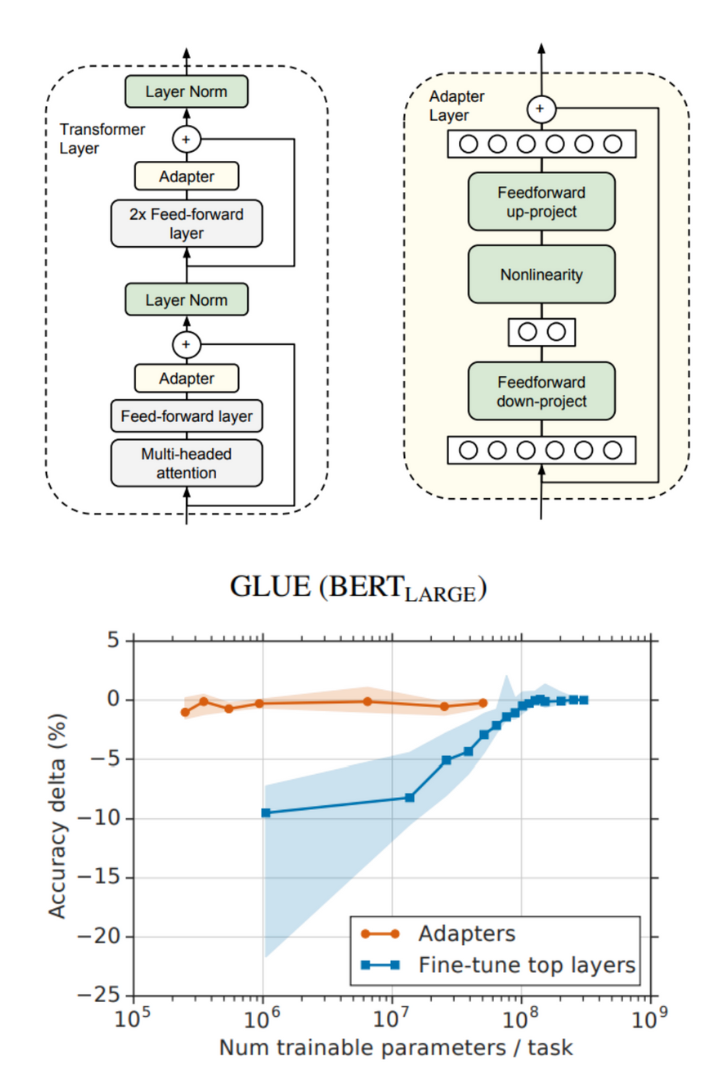
- original model parameter는 fix, adapter layer만 fine-tuning 시킴
- task별 독립성 가짐
- Feed Forward Layer 뒤에 붙임
- 3.6%정도의 파라미터만 필요
- adds latency: 언어 모델의 추론 과정에서 추가적인 계산이 필요하게 됨, 모델 크기도 증가됨
LoRA (Low Rank Adaption)
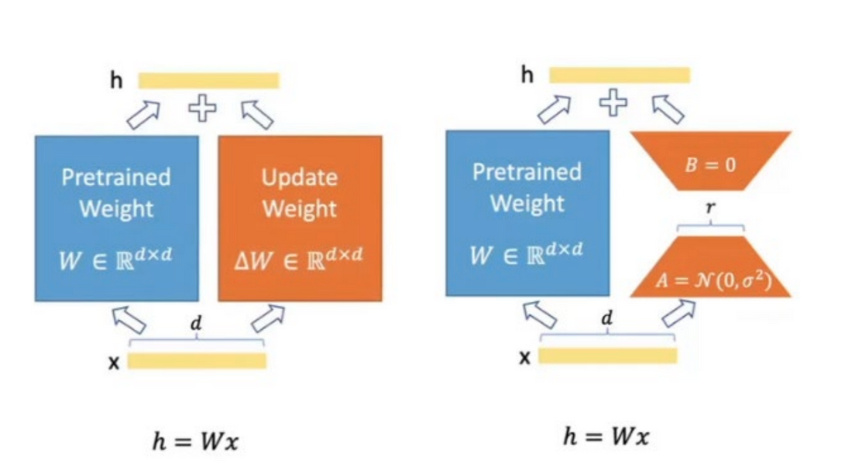
- 큰 언어 모델의 파라미터를 저차원의 부분 공간(subspace)에 투영하여 작은 부분 공간에서 파라미터를 조정함으로써 효율성을 추구
- 파라미터 matrix를 low rank의 근사 행렬로 분해
- pretrained weight는 freezing시켜두고, 일부 weight만 update 진행함
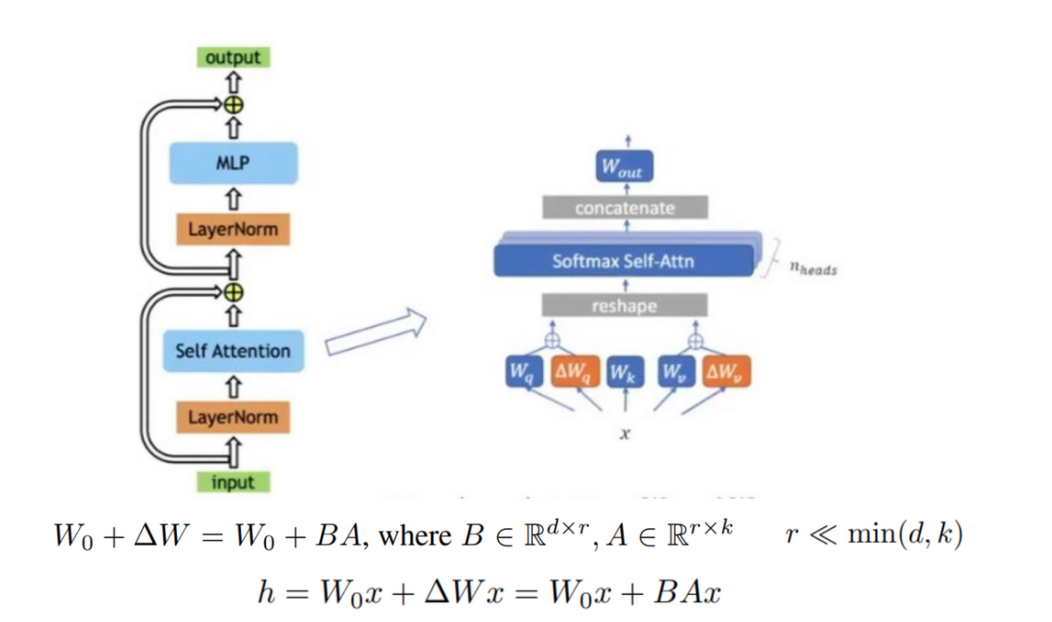
- $W_q, W_k, W_v$는 각각 query, key, value에 적용되는 weight
- $W_q, W_v$에만 LoRA 적용시켜 학습할 파라미터의 수를 줄임
- adapter와 비교하였을 때 low latency
- parallel 가능
Prefix Tuning
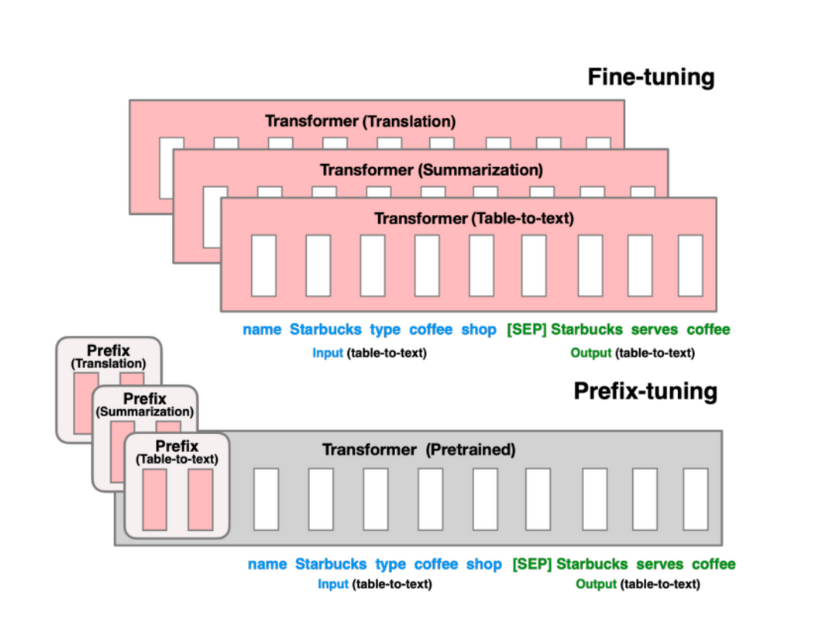
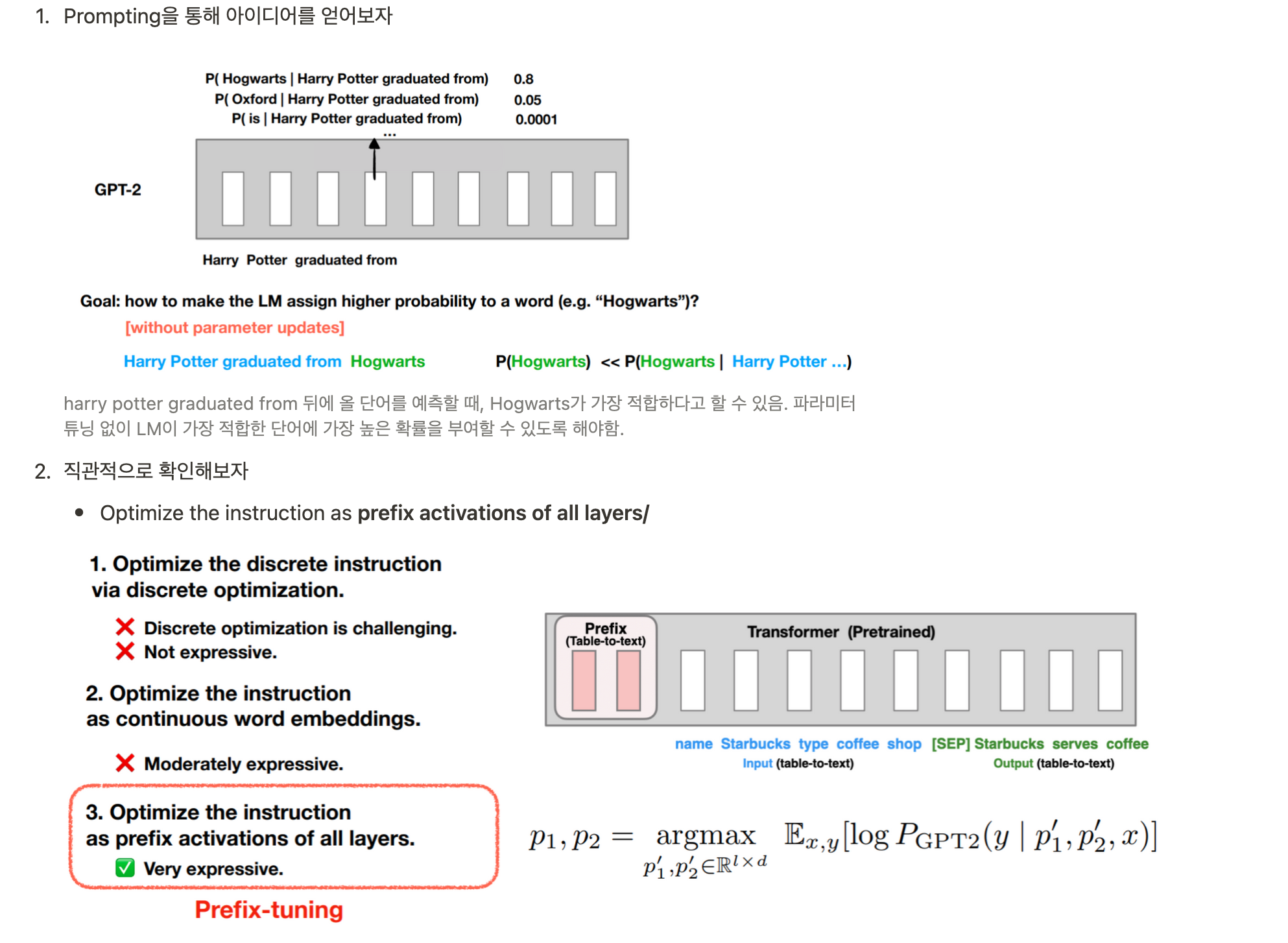
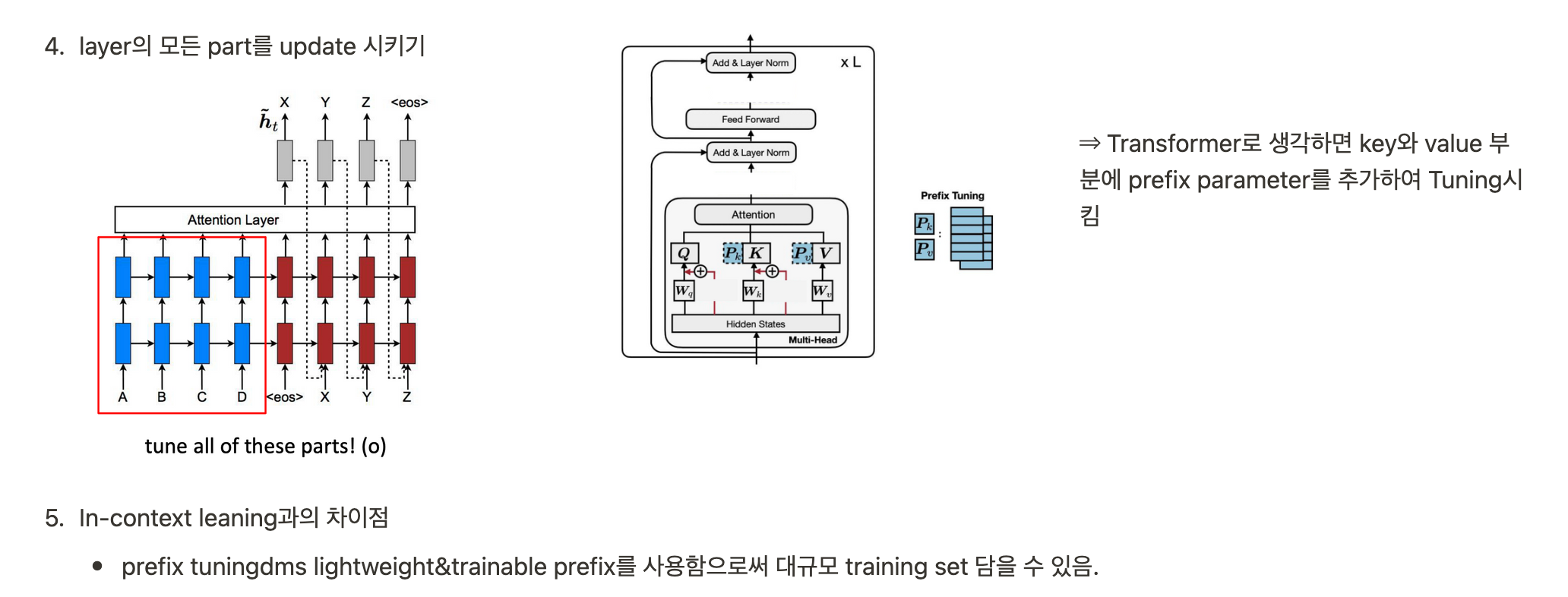
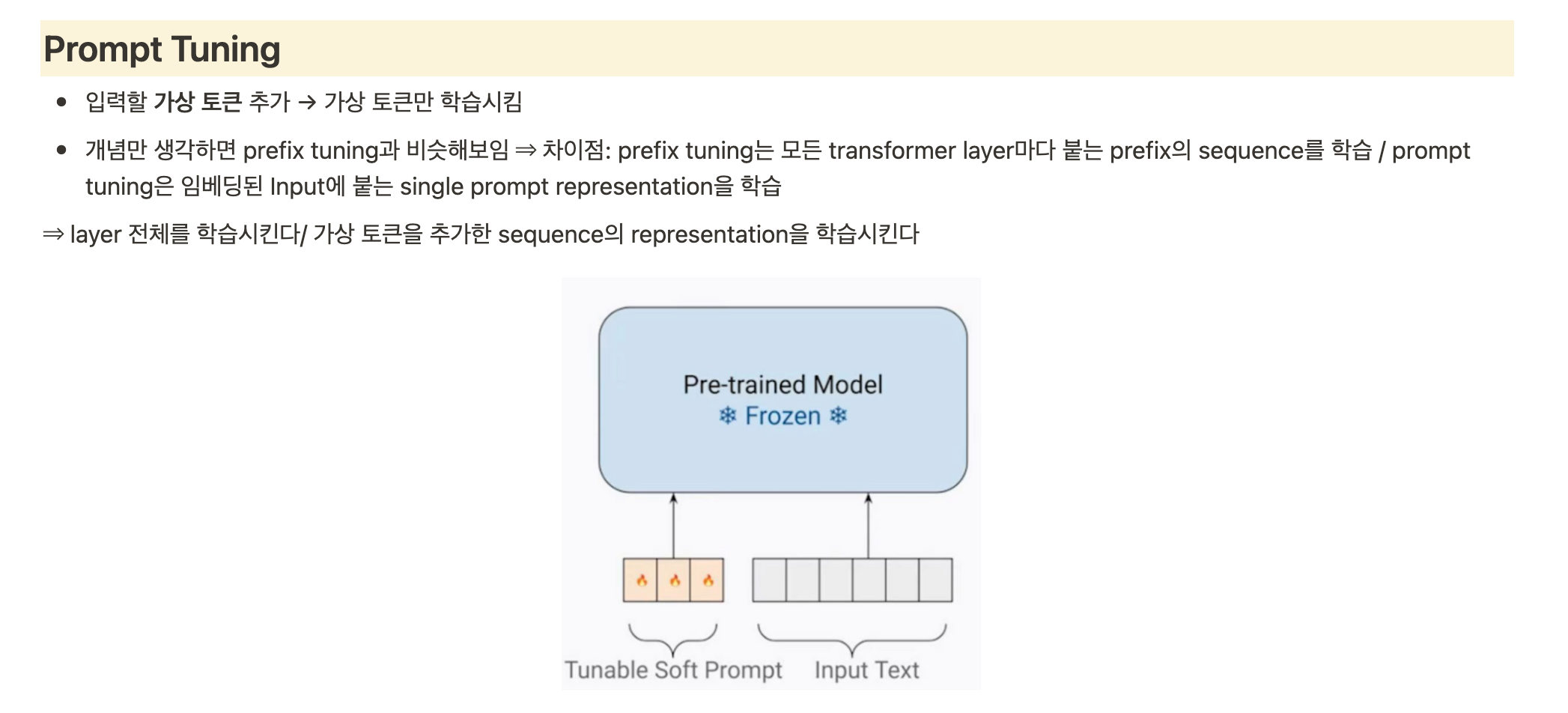
- prompt design 시에 optimize할 수 있는 방법. 개별적인 prompt를 메뉴얼하게 디자인하는 것은 힘듦.
- continous prompt를 임베딩하여 optimize
- 주어진 작업에 특화된 prefix를 추출하여 모델 조정 (ex 번역 작업에서는 특정 언어로 번역되는 문장을 시작하는 프리픽스를 정의)
- 주어진 작업에 특화된 프리픽스를 모델의 입력으로 추가하고, 해당 프리픽스를 기반으로 모델을 조정
- 프리픽스는 일반적으로 특수 토큰으로 표시되며, 모델의 입력 시퀀스의 처음에 위치합니다. 이렇게 프리픽스를 추가하면 모델은 주어진 작업에 맞는 문맥을 고려하여 다음 단어를 예측

'AI > NLP' 카테고리의 다른 글
| [NLP] Chatgpt API 사용하기/ Chatgpt를 사용한 inference (0) | 2023.06.18 |
|---|---|
| [Paper review/NLP]Tokenization Repair in the Presence of Spelling Errors (CoNLL 2021) (0) | 2023.05.23 |
| [NLP] 자연어 모델 이해하기 (2) - Seq2Seq와 Attention (0) | 2023.04.30 |
| [NLP] 자연어 모델 이해하기 (1) - NLP의 이해/ RNN / LSTM (2) | 2023.04.09 |
Backgrounds
- NLP 모델의 발전 과정
→ 모델과 데이터의 사이즈가 커짐에 따라 전체 데이터만 사용하는 방식이 아닌 다양한 방식이 도입되었음
→ 그 중 PELT는 2020년 이후로 많이 사용되었음
- Prompt-based Fine-tuning: 새로운 파라미터가 필요없고, few-shot 학습에 용이함
- In-context Learning: task에 따라 모델의 파라미터를 바꾸는 것이 아닌, 몇개의 example만을 가지고 학습하는 방식
: prompt, demonstrations, pattern, verbalizer(label과 text를 mapping해주는 함수)의 개념 활용
⇒ No task-specific training이 가능하다는 장점이 있지만, 대규모 training set를 활용할 수 없고, manually 하게 쓰여진 prompt는 best가 될 수 없음. 또한 smaller LM에 대해서는 일반화가 어려움
PELT: Parameter-Efficient LM Tuning
- parameter를 효율적으로 학습하기 위한 방법론들
- Full Fine-Tuning의 경우, 기존의 모델들에 task에 맞는 Layer를 추가하여 전체를 재학습 시켜야 했음
→ 실제로 GPT-3를 Full Fine Tuning하려면 1TB의 체크포인트와 v100 최소 96개 이상이 필요함
→ 따라서 each task마다 each model을 사용: 시간 비용 많이 소요
- 이를 해결하기 위하여 파라미터 일부만 training 시킴 (비용 절감)→ 다수의 parameter들은 frozen시킨후, task에 맞게 일부 parameter만 training 시킴
- Transformer를 다음과 같은 방식으로 효율적으로 학습 시킴(Houlsby et al., Parameter-Efficient Transfer Learning for NLP, ICML 2019) ⇒ 뒤에 자세히
⇒ Adapter, LoRA, Prefix Tuning
Adapter
- original model parameter는 fix, adapter layer만 fine-tuning 시킴
- task별 독립성 가짐
- Feed Forward Layer 뒤에 붙임
- 3.6%정도의 파라미터만 필요
- adds latency: 언어 모델의 추론 과정에서 추가적인 계산이 필요하게 됨, 모델 크기도 증가됨
LoRA (Low Rank Adaption)
- 큰 언어 모델의 파라미터를 저차원의 부분 공간(subspace)에 투영하여 작은 부분 공간에서 파라미터를 조정함으로써 효율성을 추구
- 파라미터 matrix를 low rank의 근사 행렬로 분해
- pretrained weight는 freezing시켜두고, 일부 weight만 update 진행함
- $W_q, W_k, W_v$는 각각 query, key, value에 적용되는 weight
- $W_q, W_v$에만 LoRA 적용시켜 학습할 파라미터의 수를 줄임
- adapter와 비교하였을 때 low latency
- parallel 가능
Prefix Tuning
- prompt design 시에 optimize할 수 있는 방법. 개별적인 prompt를 메뉴얼하게 디자인하는 것은 힘듦.
- continous prompt를 임베딩하여 optimize
- 주어진 작업에 특화된 prefix를 추출하여 모델 조정 (ex 번역 작업에서는 특정 언어로 번역되는 문장을 시작하는 프리픽스를 정의)
- 주어진 작업에 특화된 프리픽스를 모델의 입력으로 추가하고, 해당 프리픽스를 기반으로 모델을 조정
- 프리픽스는 일반적으로 특수 토큰으로 표시되며, 모델의 입력 시퀀스의 처음에 위치합니다. 이렇게 프리픽스를 추가하면 모델은 주어진 작업에 맞는 문맥을 고려하여 다음 단어를 예측
'AI > NLP' 카테고리의 다른 글
| [NLP] Chatgpt API 사용하기/ Chatgpt를 사용한 inference (0) | 2023.06.18 |
|---|---|
| [Paper review/NLP]Tokenization Repair in the Presence of Spelling Errors (CoNLL 2021) (0) | 2023.05.23 |
| [NLP] 자연어 모델 이해하기 (2) - Seq2Seq와 Attention (0) | 2023.04.30 |
| [NLP] 자연어 모델 이해하기 (1) - NLP의 이해/ RNN / LSTM (2) | 2023.04.09 |