
Paper Main Idea
- 맞춤법 오류가 있는 텍스트에 대해서 tokenizatioin repair를 수행함으로써 맞춤법 교정 수행
- 왜 tokenization 과정에서 수행하였는가?
- 우선 토큰화는 자연어 처리에서 가장 중요하다고 해도 과언이 아닌 단계임 (토큰화 : 텍스트를 의미가 있는 가장 작은 단위로 분할하는 과정)
- 맞춤법 오류가 있는 텍스트의 경우 토큰화 단계에서부터 문제가 발생할 수 있음
- ex) "This algoritm runs in linear time"→ This, algoritm, runs, in, linear, time로 분리되어야 함.
- This algor itm runsin linear time 처럼 띄어쓰기 단계에서 오타가 있는 경우는 올바른 토큰으로 분리되지 않을 수 있음
- tokenization fix와 spelling fix를 동시에 수행할 수 있도록 함
- → 기존 연구는 토큰화가 잘 이루어졌을 것이라 가정하고 spell fix를 하거나 토큰화 fix를 제한적으로만 수행할 수 있었음
- 이미 존재하는 공백 정보를 활용하도록 함
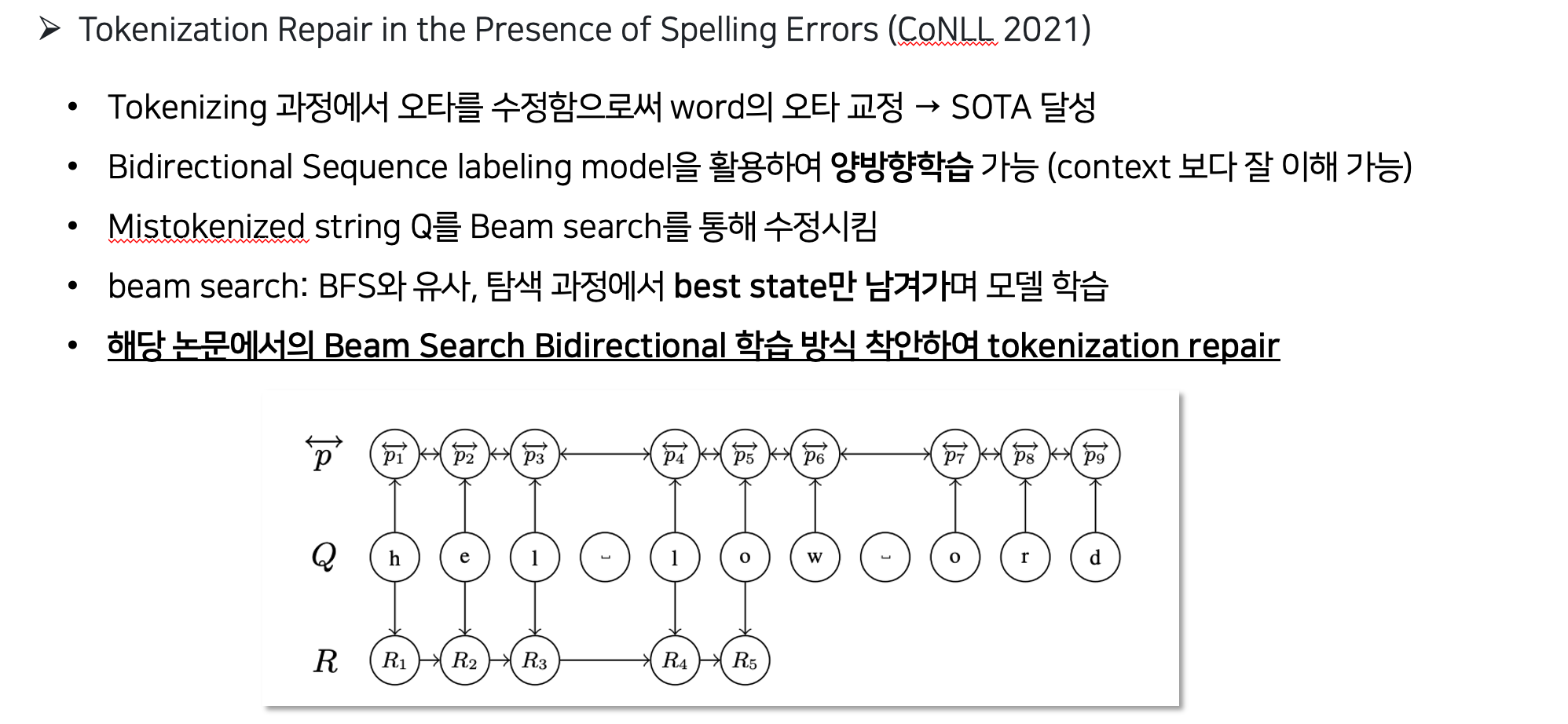
- beam search + 양방향 정보 포함
- 이미 존재하는 error 관련 벤치마크 데이터셋 모두에 범용적으로 활용할 수 있는 모델을 구축함
Method
beam search based on deep character-based models, unidirectional and bidirectional.
Beam search bidirectional (BID): UNI with the bidirectional labeling model
- Unidirectional language models (UNI)+ Bidirectional sequence labeling model
- Unidirectional language models (UNI): character based LM은 문자열에 있는 개별 문자의 확률을 기반으로 some 언어에서 문자열이 발생할 확률을 추정함.→ 주로 RNN 계열 모델 활용 (LSTM cell)
- ⇒ 1024 unit LSTM cell 활용, dense layer(ReLU, softmax(for classification))
- Bidirectional: bidirectional LSTM cell with 1024 units 활용→ context 보다 잘 이해 가능할 수 있도록 함 <12,158,980 trainable parameters>
- Beam Search : BFS와 유사함. 탐색 과정에서 best state b만 남겨가면서 학습 진행함
- Beam Search 방법론과 양방향 개념을 조합한 BID 방법
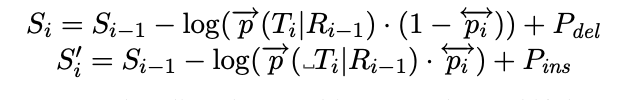
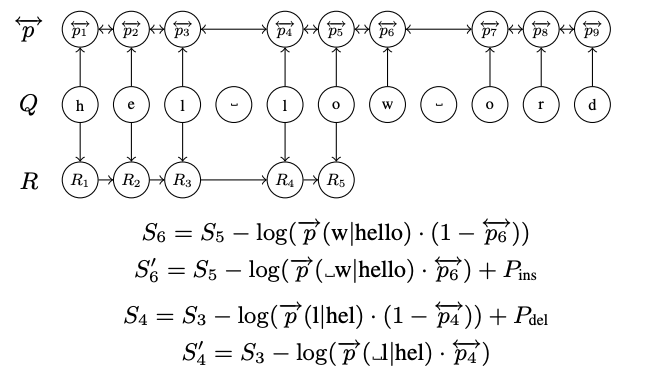
Mis token Q: “hel low ord”
R: 수정된 결과 (R5는 hello)
p: 단어 간 양쪽을 고려하는 확률
Baseline approach
- Dynamic programming bigram model
- wordsegment
- Google spell checker
Source Data of tokenization error
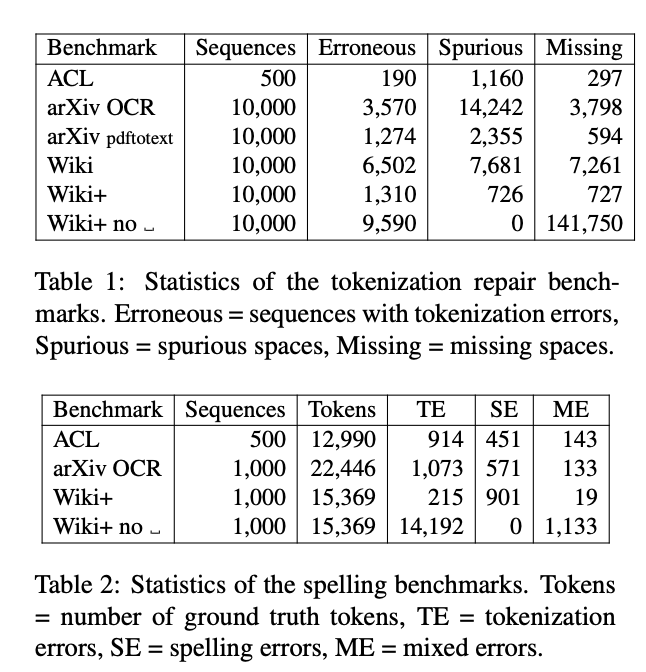
- 해당 논문에서는 에러를 학습시키기 위한 source 데이터로 6개의 benchmark data를 사용하고 있음.
- ACL: scientific articles published between 1965 and 2012, corrected the tokenization and spelling of 500 sequences for development and penalty optimization, and 500 sequences as a test set
- arXiv OCR: 910,000 articles from arXiv
- arXiv pdftotext
- Wiki: articles from Wikipedia3 using WikiExtractor
- Wiki+
- Wiki+no
- error 종류 : OCR error, Human error
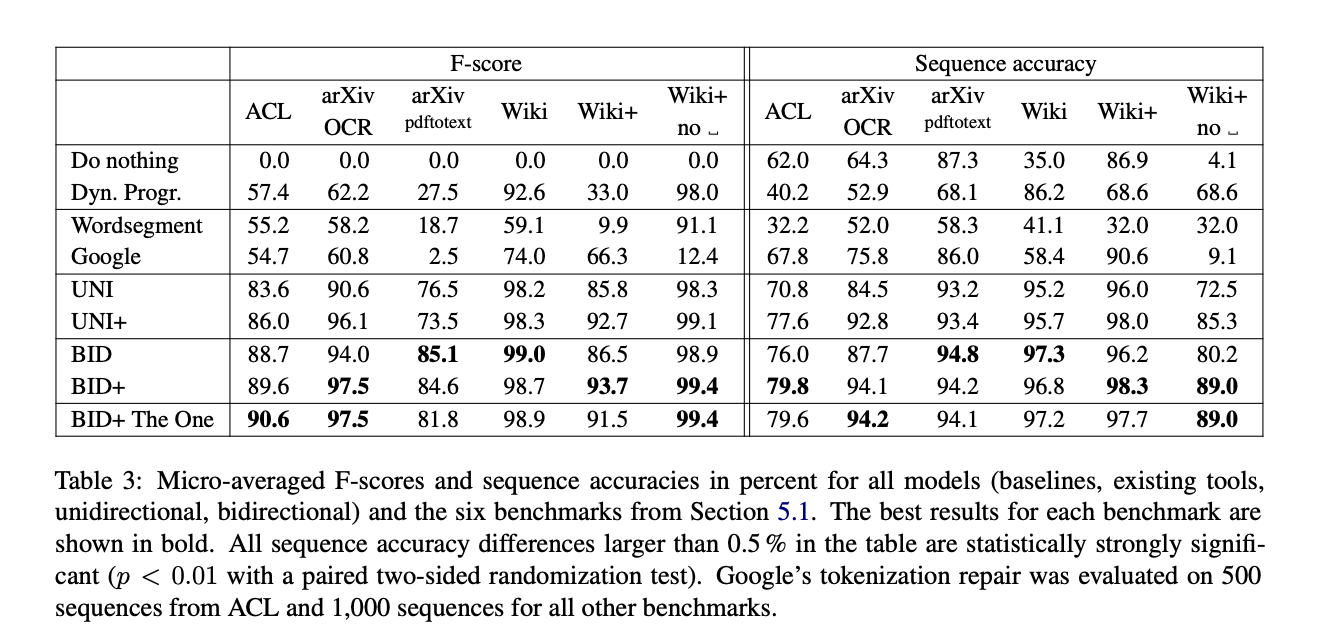
Experiment
- F-score
- Sequence accuracy

300x250
'AI > NLP' 카테고리의 다른 글
| [NLP] Parameter efficient LM tuning (0) | 2023.07.02 |
|---|---|
| [NLP] Chatgpt API 사용하기/ Chatgpt를 사용한 inference (0) | 2023.06.18 |
| [NLP] 자연어 모델 이해하기 (2) - Seq2Seq와 Attention (0) | 2023.04.30 |
| [NLP] 자연어 모델 이해하기 (1) - NLP의 이해/ RNN / LSTM (2) | 2023.04.09 |