
언어 모델의 발전 과정을 전체적으로 톺아보기 위한 포스팅이다.
(1) NLP의 이해/ RNN / LSTM
(2) Seq2seq / Transformer
(3) Transformer 계열 모델 - encoder only / encoder-decoder / decoder only
(4) In context learning
(5) promting for few-shot learnig
순서로 전체적인 흐름을 정리해본다. (추후 순서 변경 가능!)
NLP의 의미
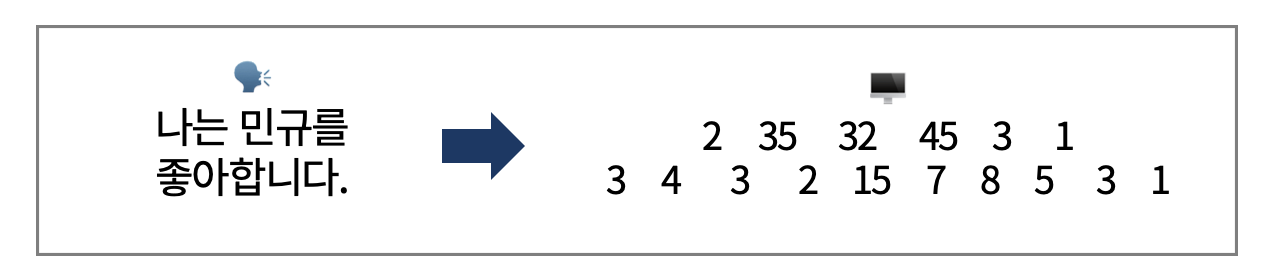
NLP(Natural Language Processing)는 말 그대로, 컴퓨터가 인간의 언어를 이해할 수 있도록 하는 전반적인 과정을 다루는 AI 분야이다. 컴퓨터가 이해할 수 있도록 언어를 바꾼 후 , 추론 및 문장 생성 등 다양한 언어 Task를 수행하도록 한다. 다음과 같은 예시처럼 인간의 언어를 벡터로 변환하여 컴퓨터의 언어로 바꾸는 과정을 수행한다.
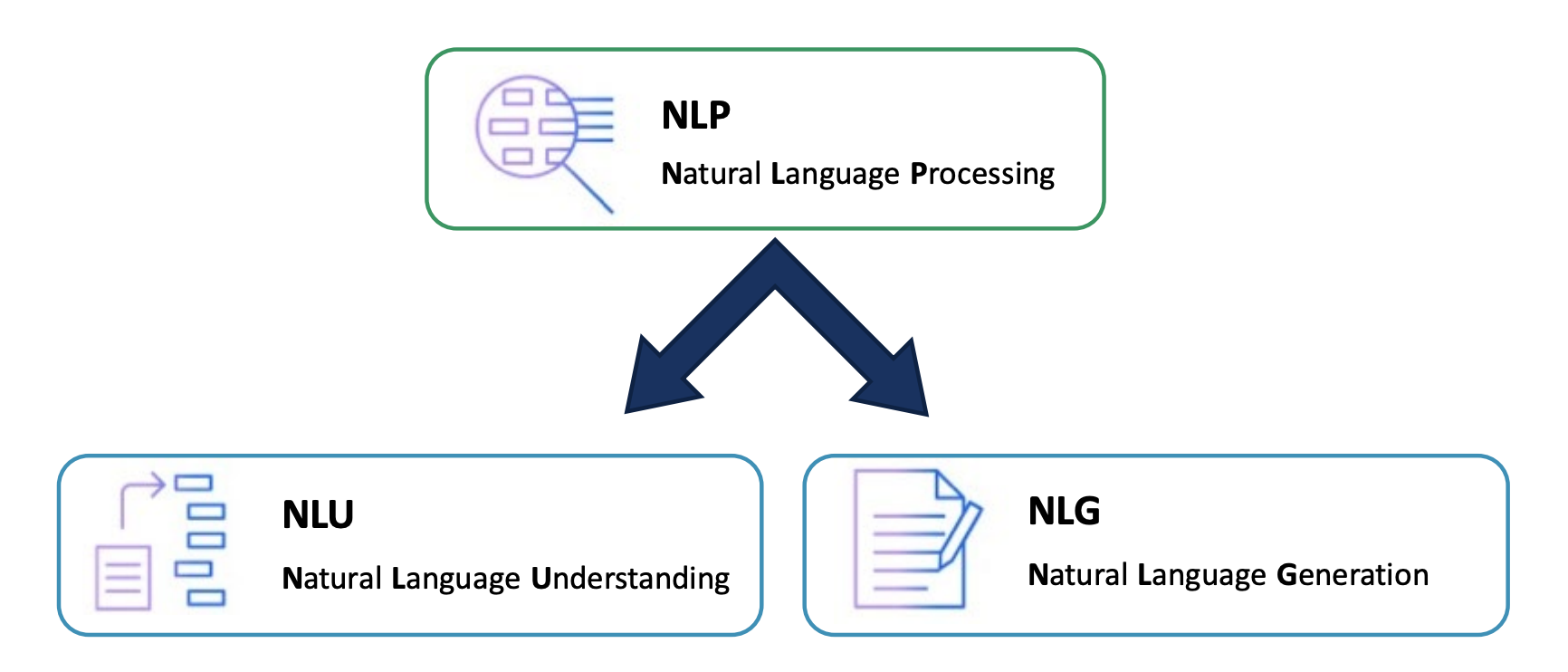
NLP의 과제는 크게 NLU와 NLP로 나뉜다. NLU는 Natural Language Understanding으로 대부분의 classification task가 해당된다. NLG는 Natural Language Generation으로 언어 생성 task가 해당된다. 머신러닝 테스크가 크게 classification과 regression으로 나뉘는 것과 유사하다고 생각할 수 있다.
Buliding NLP Systems
NLP, 즉 언어 모델을 구축하는 과정은 크게 전처리 -> 임베딩 -> 모델링 세 부분으로 나눌 수 있다.
"I loved the movie"라는 문장이 긍정인지 부정인지 분류하는 task를 수행한다고 해보자. 이 문장은 I, loved, the, movie의 subword로 나눠진 후, N*D 의 vector로 embedding된다. 그 후 언어 모델을 활용하여 최종 분류 문제를 수행하게 된다. 각 과정을 세부적으로 설명해보겠다.
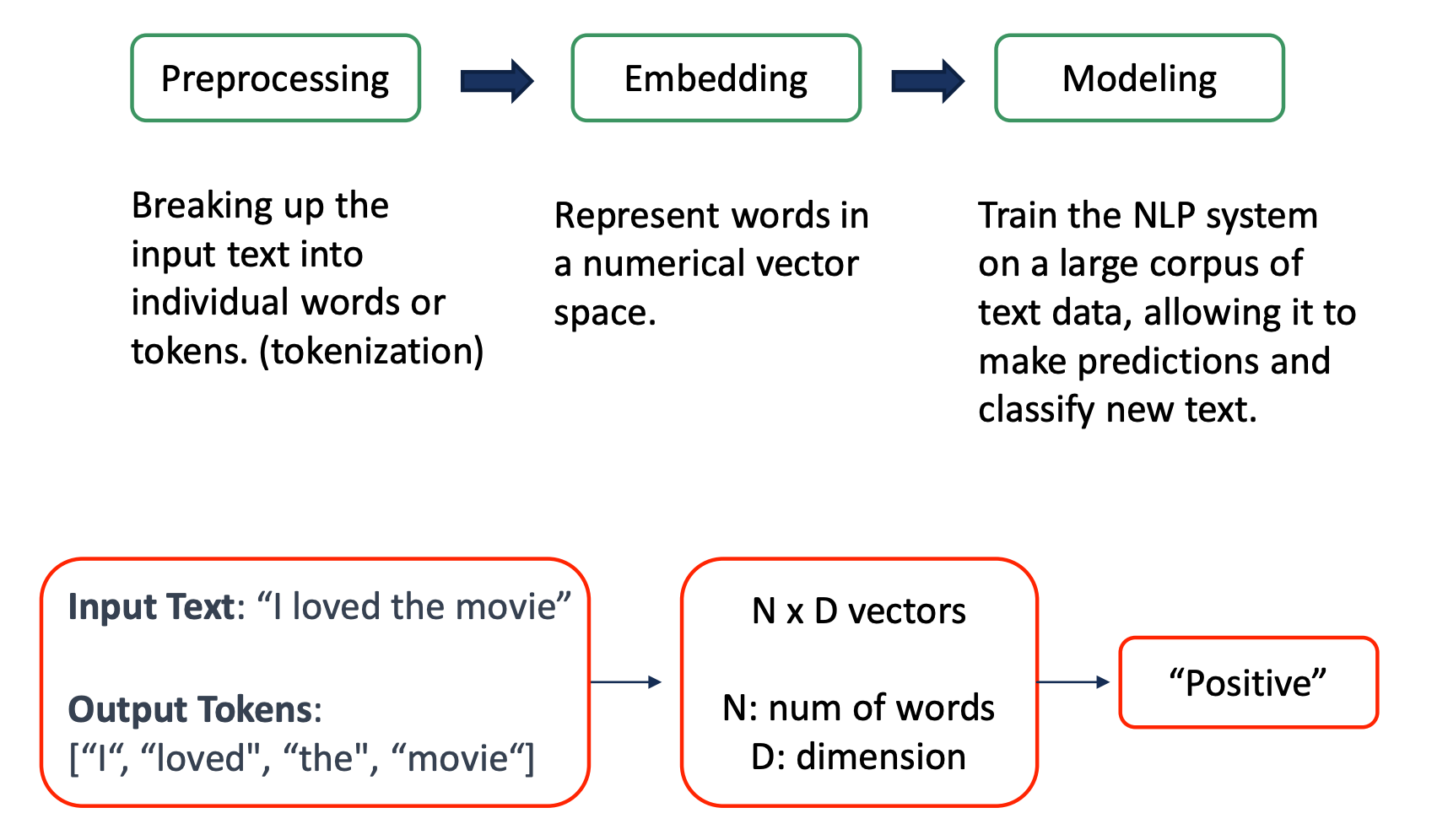
- preprocessing: 문장을 단어 단위로 쪼개는 과정이다. 나아가서는 subword, charactor 단위까지 나누기도 한다. 긴 문장은 모델이 이해하기 어렵기 때문에 모델이 이해할 수 있는 형태로 만드는 것이다. 이러한 과정을 tokenization이라고 한다. 많은 tokenizer가 배포되어 있으므로, 상황에 맞는 것을 골라 사용할 수 있다

2. Embeding: 모델이 이해할 수 있는 벡터로 만드는 과정이다. 단어를 벡터 space 상으로 표현하는 것으로 숫자들로 단어 표현한다. 신경망에 넣기 위해서는 input의 형태가 벡터여야 하기 때문에 해당 과정을 거쳐 모델에 입력하고, 유의미한 값을 얻고자 한다. word embeding 과정에서 vector space상 거리를 계산하여 단어의 유사도를 계산하기도 한다.
3. Modeling: 다양한 모델 활용하여 task 수행한다. 다음은 "I am a good" 다음에 올 단어를 예측하는 task이다. input으로 word vector의 sequence를 받아 내부 연산을 거쳐 output으로 다음 단어가 올 확률을 계산한다. 그 후 관측될 확률을 고려하여 높은 확률의 단어를 선택한다.
이것은 하나의 예시로, task에 맞는 다양한 언어 모델을 사용할 수 있다.
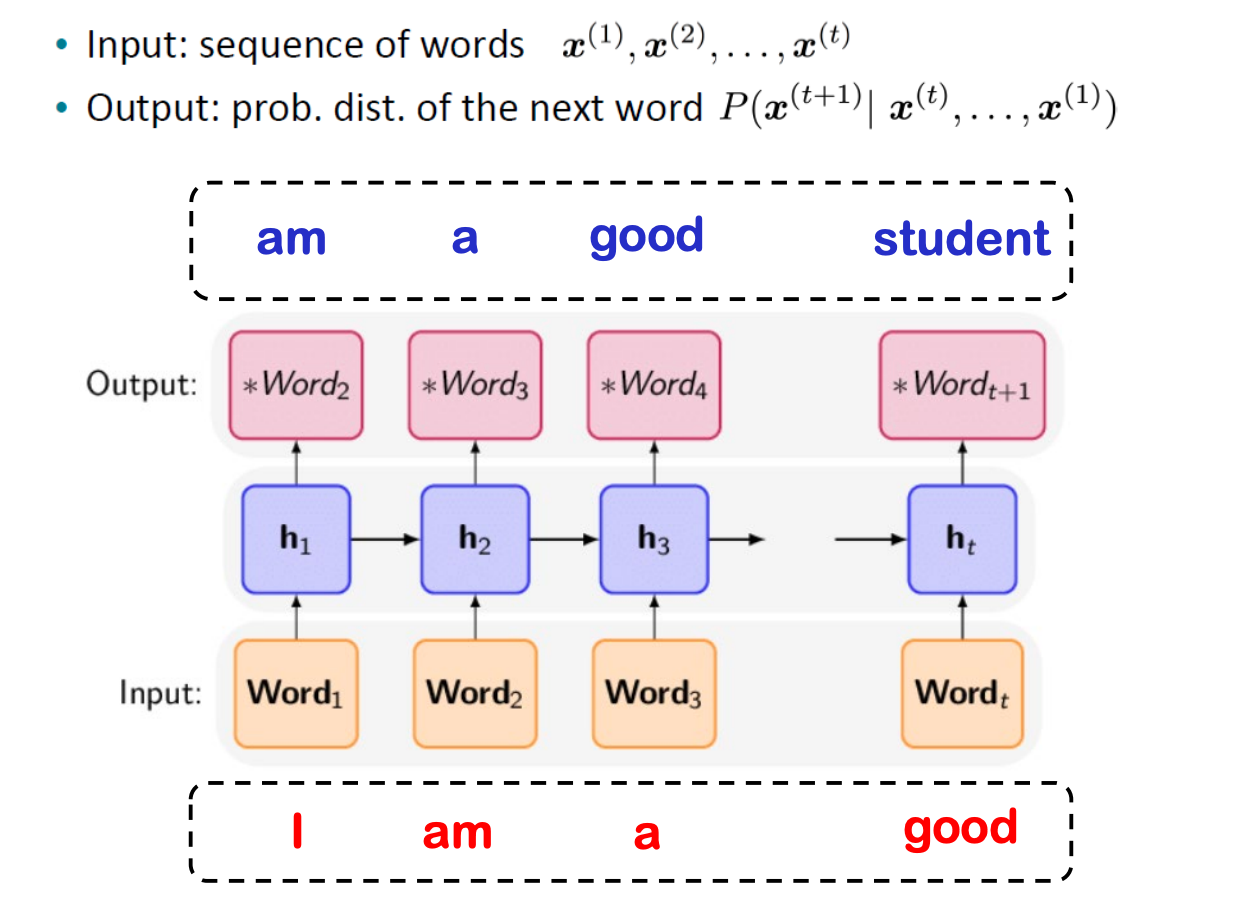
여기서 word ordering이라는 개념을 생각할 수 있다. 단어를 순서대로 처리하기 때문에 언어 모델은 seqeuntial data를 효율적으로 처리할 수 있어야 한다. 여기서 자연스레 언어 모델에 RNN을 도입하는 방안이 제안되었다.
RNN and LM
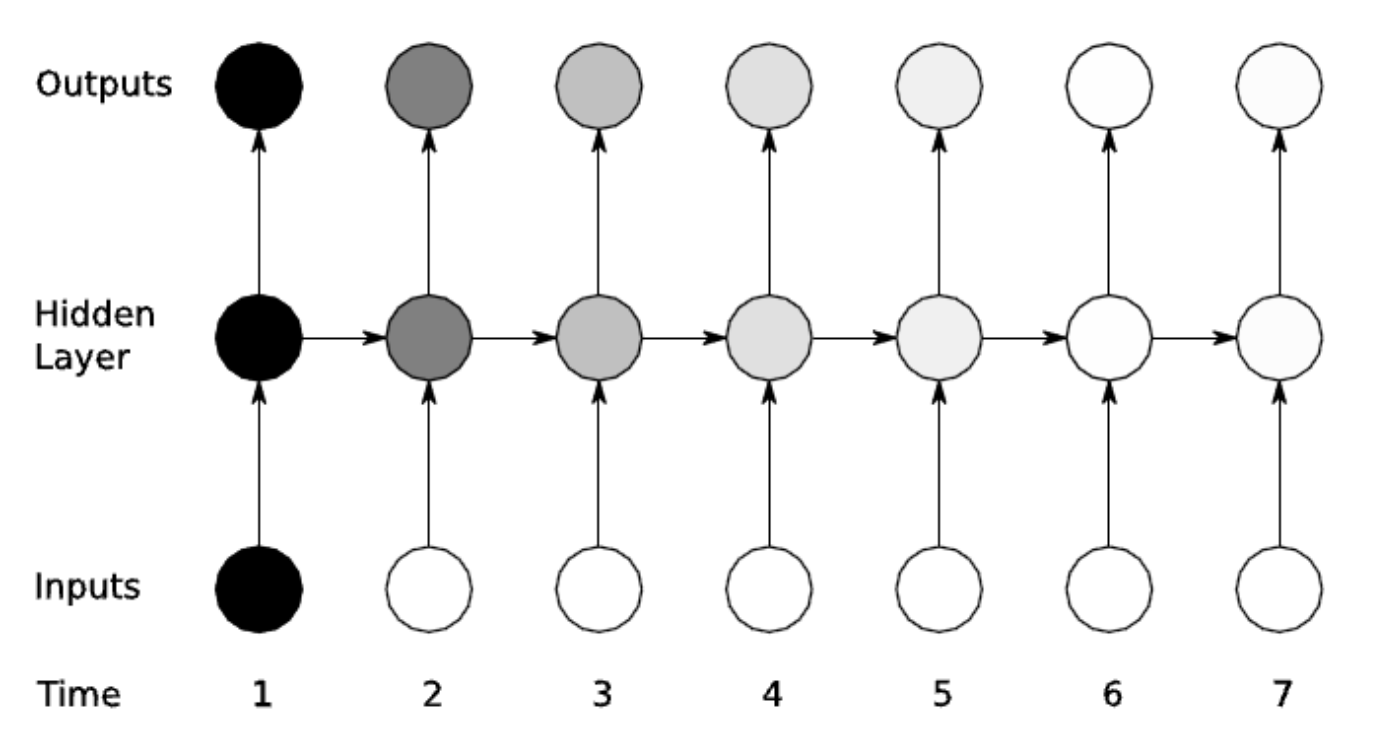
RNN은 sequential time series data에 적합하다고 알려진 모델이다. Time step을 거치면서 output이 input으로 다시 들어가는 방식으로 학습이 이루어 진다. hidden state s_t는 그 전 타임의 정보를 담고 있다. t+1번째의 셀은 현재 정보와 과거 정보의 가중합으로 이루어진다.
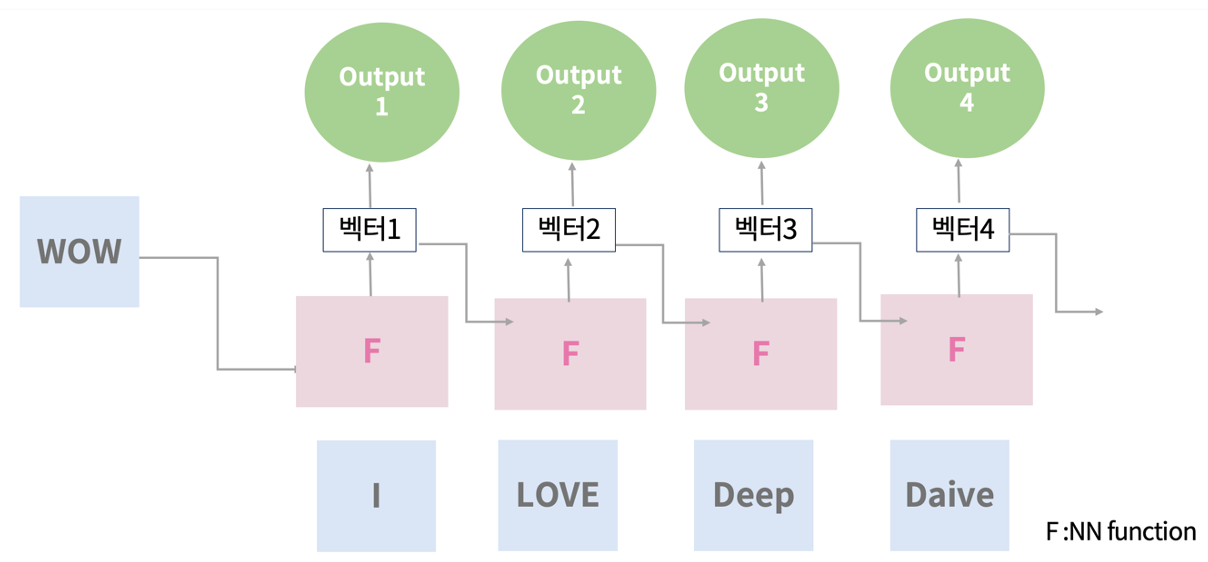
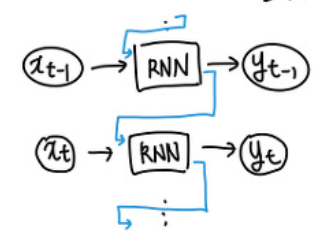
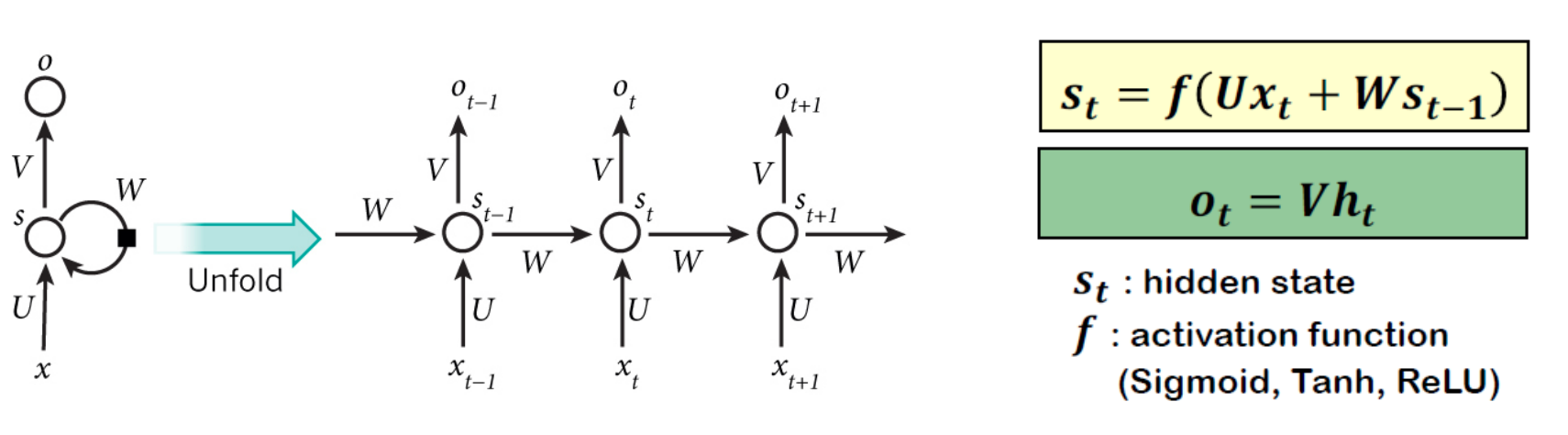
구조 매우 간단하며 문장의 의미를 압축할 수 있다는 장점이 있어 이미지 캡셔닝, 감정 분류, 기계 번역, 비디오 분류 등 많은 곳에 쓰일 수 있다. 하지만 요즘은 모델의 발전으로 많이 쓰이지는 않는다.
언어 모델에 적용한다면, 생성할 단어에 대한 distribution을 구해 hidden state에 기본 정보 저장하고, 다음 단어로 넘어간다. 해당 과정을 통해 마지막 단계에서 누적 정보를 바탕으로 마지막 단어를 예측한다.
Vanishing Gradients in RNN
RNN에서는 vanishing gradient 문제가 발생할 수 있다. 이는 미래 시점으로 갈 수록 과거의 정보가 희미해지는 것을 의미한다. hidden layer가 저장할 수 있는 정보의 양에는 한계가 있으므로 과거의 정보가 누락될 수 있는 것이다. 이는 초기의 정보가 뒤쪽 layer로 갈 수록 흐려지기 때문에 발생한다.
이러한 단점때문에 LSTM이 제안된다.
LSTM-RNNS / GRU
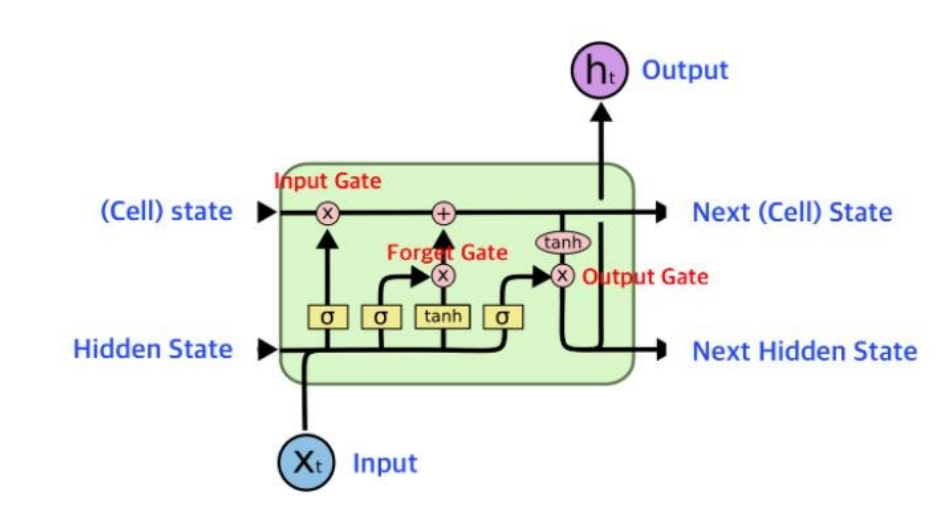
RNN의 단점을 보완하기 위해 제안된 LSTM은 정보를 선택하여 지속적으로 초기 정보를 보관할 수 있도록 한다. 이를 위해 memory cell 구조를 제시한다. t에 걸쳐 어떤 정보를 유지하며 다음 step t로 넘어가는 neural network 구조로 정보를 선택적으로 읽고 쓸 수 있도록 한다. 과거의 정보를 어느 정도 유지해야할 지 gate를 통해 판단하는데, input, forget, output의 3개의 gates를 사용한다. input gate의 일부 정보를 next cell state에 저장하고, forget gate를 통해 중요하지 않은 정보를 필터링하여 넘긴다. 위의 과정을 통해 초기 중요 정보를 누락하지 않고 끝까지 유지할 수 있다.
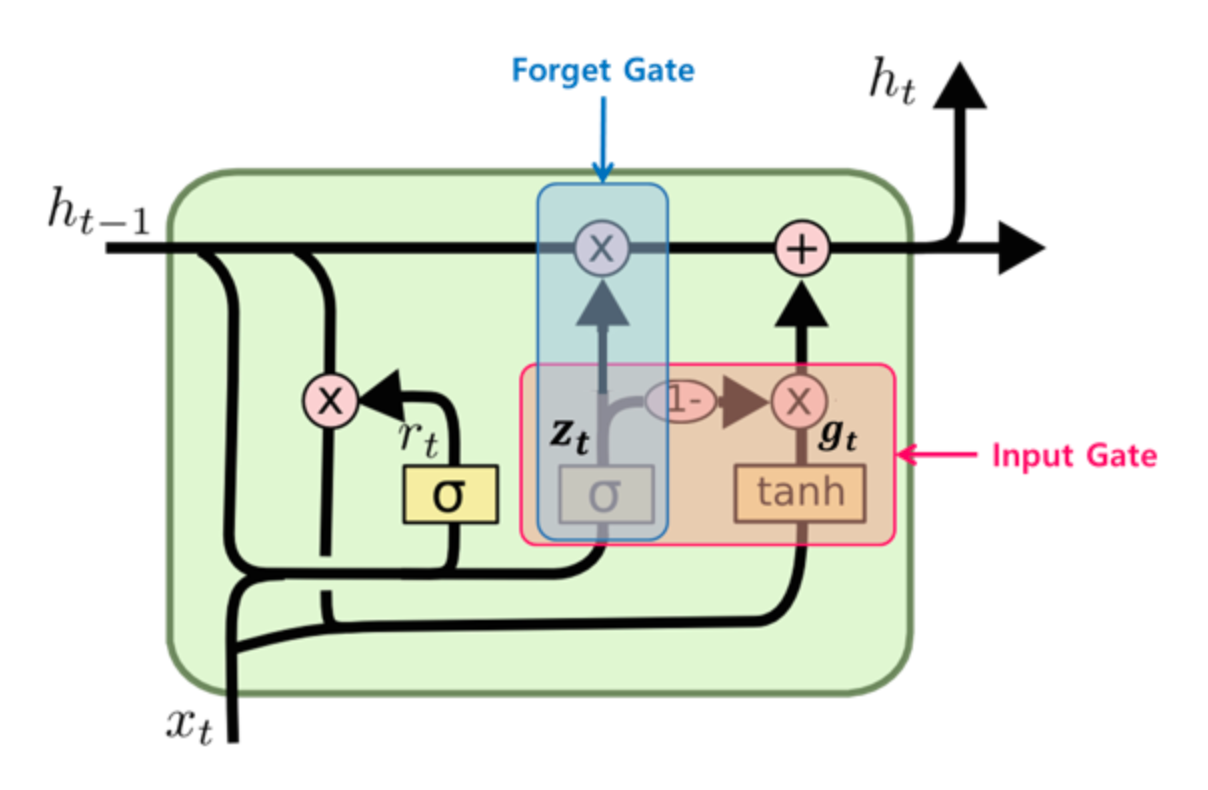
추후에는 개선된 GRU도 제안되었는데, LSTM의 간소화 버전이라고 할 수 있다. forget, input gate를 하나의 gate controller가 관리한다.
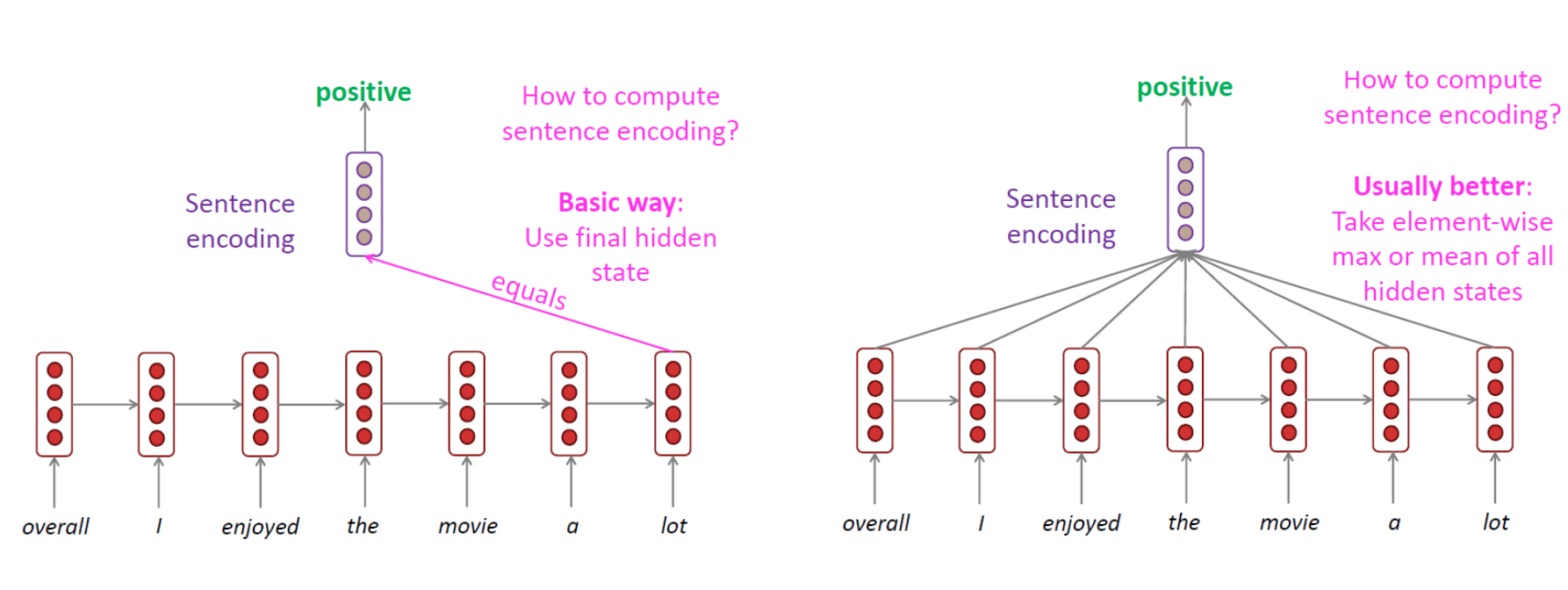
RNN for encoding sentense
해당 과정은 RNN을 사용하여 문장을 인코딩하는 예시이다. RNN representation을 통해 문장을 인코딩하여 추후 문장 감정 분류에 사용될 수 있다.
[Reference]
중앙대학교 AI학과 이환희 교수님 ANLP 수업 내용에 개인적인 공부 내용을 더해 작성되었습니다.
'AI > NLP' 카테고리의 다른 글
| [NLP] Parameter efficient LM tuning (0) | 2023.07.02 |
|---|---|
| [NLP] Chatgpt API 사용하기/ Chatgpt를 사용한 inference (0) | 2023.06.18 |
| [Paper review/NLP]Tokenization Repair in the Presence of Spelling Errors (CoNLL 2021) (0) | 2023.05.23 |
| [NLP] 자연어 모델 이해하기 (2) - Seq2Seq와 Attention (0) | 2023.04.30 |