
독성 예측 분야에서의 class imbalance
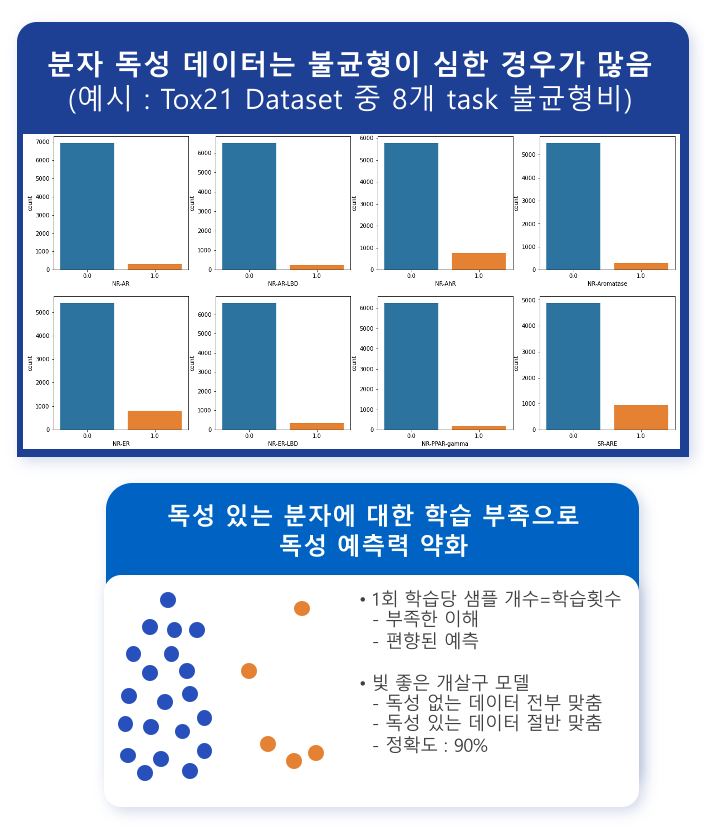
분자의 독성 데이터는 불균형이 심한 경우가 많다. 데이터 불균형이란 라벨 간의 수의 차이가 심한 경우를 의미한다.
독성 예측의 benchmark dataset인 molecular data의 Tox21 데이터는 8개의 라벨에서 심한 불균형을 보였다.
이것이 왜 문제가 될까? 바로 독성 있는 분자에 대한 학습의 부족으로 예측력이 약화될 수 있다.
accuracy는 높지만 전부 0으로 때려 맞춰서 정확도가 높게 나온 것일 뿐, 1인 것에 대해서는 정확히 예측하지 못한 것이다.
SMOTE(Synthetic Minority Over-Smapling Techniques)
대표적인 oversampling 기법으로, 독성 예측 분야에도 물론 적용이 가능하다. 물론 대부분의 molecualrnet 데이터들은 multi-label이기 때문에 단순한 적용은 지양된다. Mulilabel SMOTE를 이해하기 위해서는 우선 자세히 생각해보자.
SMOTE 알고리즘을 자세히 알아보고자 한다.

'AI > Toxicity Prediction' 카테고리의 다른 글
| [Toxicity Prediction] 독성 예측과 GNN (0) | 2024.01.07 |
|---|---|
| [Toxicity Prediction] 분자를 graph로 표현하기/ graph representation (1) | 2023.05.09 |
| [Toxicity Prediction] fingerprint / ECEP(extended-connectivity fingerprint) (0) | 2022.06.06 |
| [Toxicity Prediction] 파이썬으로 SDF 파일 읽기/ 분자 데이터 SMILES식 확인하기 (0) | 2022.05.02 |
| [Toxicity Prediction]Graph Learning / molecule (분자) data training의 과제 (0) | 2022.04.17 |