[Python/ EDA] categorical data를 다루는 방법 : onehot encoding/ label encoding
Category variable / Numerical variable
데이터 분석을 진행하다보면 크게 두가지 유형의 변수를 확인할 수 있다.
numerical 변수는 말 그대로 수치형으로 된 변수이며, 데이터 정보를 확인해보았을 때 int(정수) 또는 float(실수)로 나온다. category 변수는 object 로 되어 있으며 데이터가 문자로 되어 있는 경우이다.
df.info()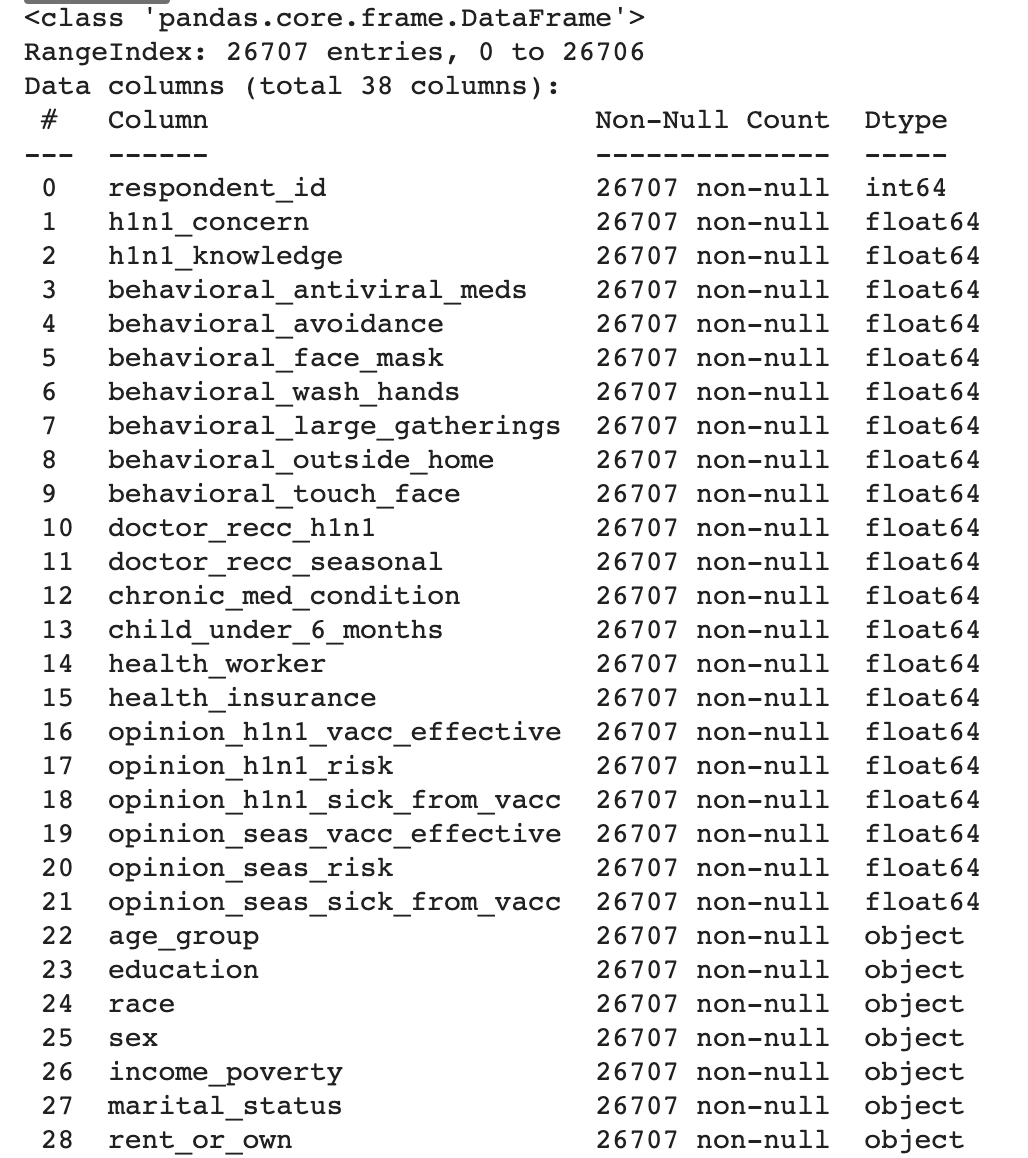
https://www.drivendata.org/competitions/66/flu-shot-learning/page/211/
질병 관련 설문조사 데이터 정보의 일부를 확인해보았다. Dtype에 float64로 나온 변수는 numerical, object로 나온 변수는 categorical 변수이다.
이러한 categorical data는 encoding 과정을 통해 문자를 컴퓨터가 인식할 수 있는 숫자 형태로 변환시켜주어야한다.
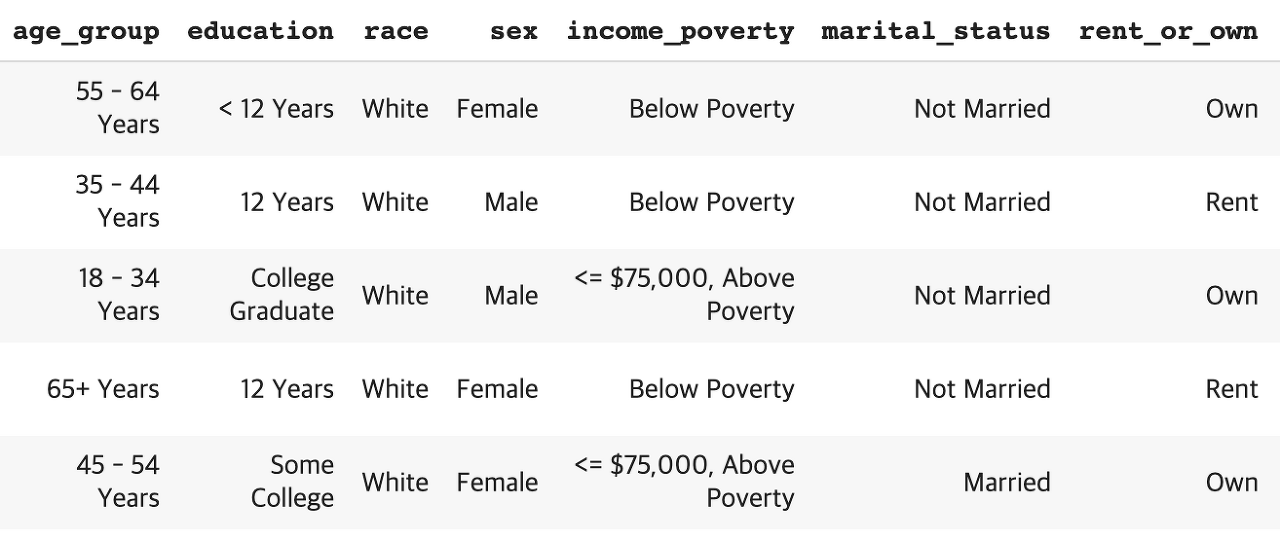
숫자로 변환시켜줄 수 있는 방법으로는 두가지 방법이 있다.
1. Onehot encoding : 순서가 없을 때
2. Label encoding: 순서가 존재할 때
Onehot encoding
원핫인코딩은 성별, 인종, 국가 등 순서가 없을 때나 고유값의 개수가 많지 않을 때 사용된다. 순서가 없더라도 고유값이 20개라던가 그 이상일 경우 20개의 더미 변수가 생기기 때문에 효율적이지는 못하다.
onehot encoding은 해당되면 1로, 아니라면 0으로 변환해준다. Female, Male로 이루어진 sex 변수가 있다면
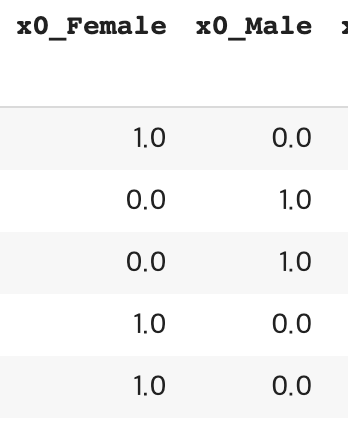
이런 식으로 해당 여부에 따라 0,1로 나타내준다.
💻 Onehot encoding function
from sklearn.preprocessing import OneHotEncoder encoder = OneHotEncoder() def onehot(col): encoder.fit(df[[col]]) onehot = encoder.transform(df[[col]]).toarray() onehot = pd.DataFrame(onehot) onehot.columns = encoder.get_feature_names() return onehot
✅ sklearn의 전처리 패키지 중 onehotencoder를 사용하며, 인코더를 활용하여 데이터를 피팅 시키고 변환시킨다.
encoder.fit(df[['sex']])
onehot = encoder.transform(df[['sex']])
onehot
✅ 출력 결과를 array 형태로 받고, 데이터프레임 형태가 전처리에 용이하므로 데이터프레임으로 변환시켜준다.
onehot.toarray()
onehot = pd.DataFrame(onehot)
onehot
✅ 칼럼명이 0,1로 되어 있으면 어떤 것을 나타내는지 확인하기 어려우니 feature의 이름을 가져와 컬럼명으로 지정한다.
onehot.columns = encoder.get_feature_names()✅ 함수를 불러와 여러 변수를 한번에 인코딩할 수 있다.
sex_onehot=onehot('sex')
rent_onehot=onehot('rent_or_own')
marital_onehot=onehot('marital_status')
em_sta_onehot=onehot('employment_status')
race_onehot=onehot('race')
census_onehot=onehot('census_msa')❗️쉽게 더미변수를 바로 생성해주는 방법도 있다.
pd.get_dummies(df[col])판다스의 더미변수 생성 함수 get_dummies를 통해 간단히 만들어줄 수 있다.
Label encoding
라벨인코딩은 주로 순서의 개념을 가지는 경우 사용된다. 나이, 교육 수준 등 순서와 순위의 개념을 가질 때 사용할 수 있다.
💻label encoding code
from sklearn import preprocessing label_encoder=preprocessing.LabelEncoder() df['age_group']=label_encoder.fit_transform(df['age_group'])해당 코드는 원핫 인코딩 코드와 달리 (array로 변환하여 데이터프레임에 적용하고 원본 데이터와 합치는 과정 없이) 바로 데이터의 값을 변환해서 추가해주는 코드이다.
0,1,2,3... 이런 식으로 숫자가 매겨진다.